PromptSep:
Generative Audio Separation via Multimodal Prompting
Yutong Wen1,2,
Ke Chen1,
Prem Seetharaman1,
Oriol Nieto1,
Jiaqi Su1,
Rithesh Kumar1,
Minje Kim2,
Paris Smaragdis3,
Zeyu Jin1,
Justin Salamon1
1 Adobe Research
2 University of Illinois Urbana-Champaign
3 MIT
Model Overview
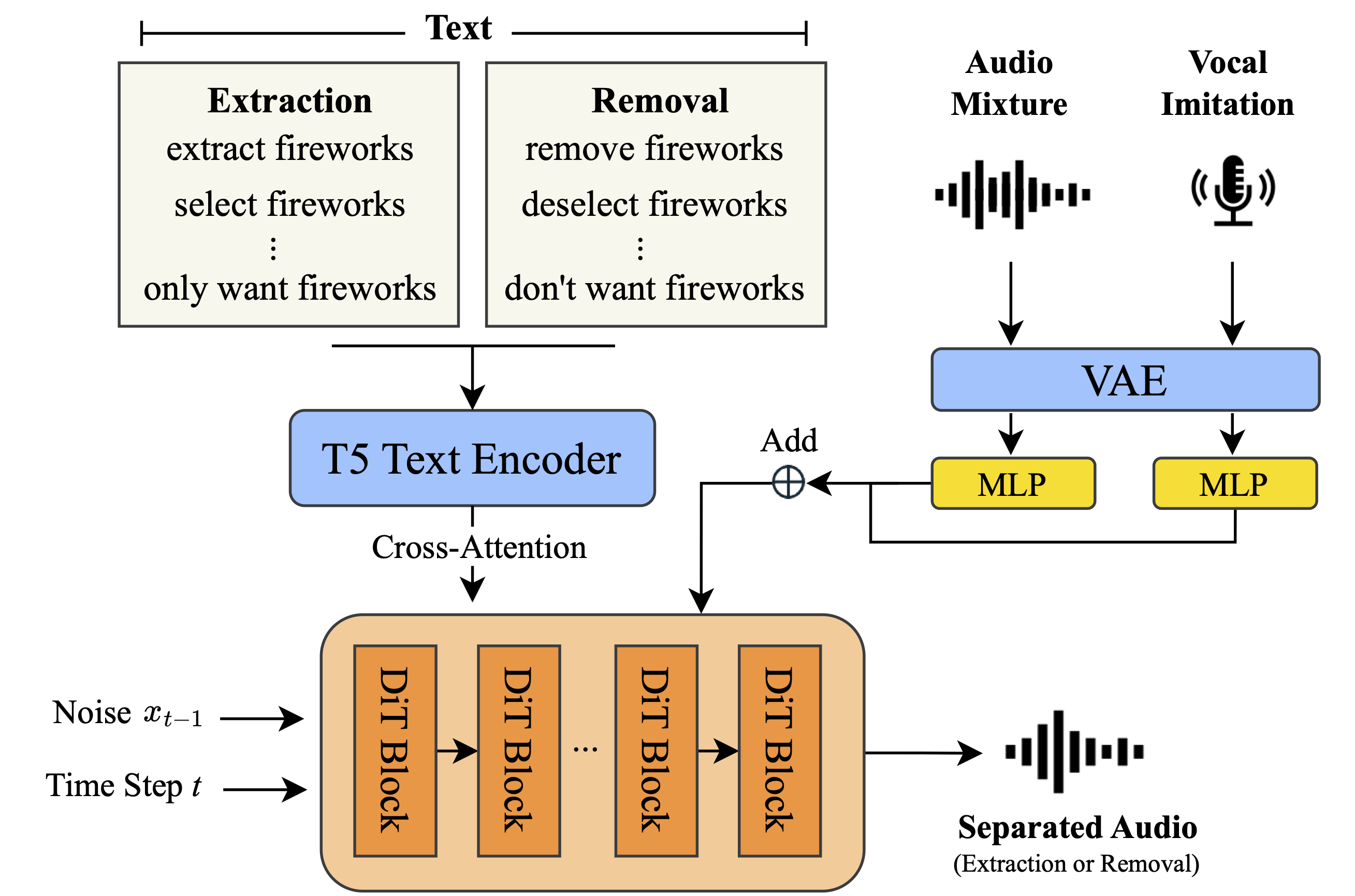
Abstract.
Recent breakthroughs in language-queried audio source separation (LASS) have shown that generative models can achieve higher separation audio quality than traditional masking-based approaches.
However, two key limitations restrict their practical use: (1) users often require operations beyond separation, such as sound removal; and (2) relying solely on text prompts can be unintuitive for specifying sound sources. In this paper, we propose PromptSep to extend LASS into a broader framework for general-purpose sound sepration. PromptSep leverages a conditional diffusion model enhanced with elaborated data simulation to enable both audio extraction and sound removal. To move beyond text-only queries, we incorporate vocal imitation as an additional and more intuitive conditioning modality for our model, by incorporating Sketch2Sound as a data augmentation strategy. Both objective and subjective evaluations on multiple benchmarks demonstrate that PromptSep achieves state-of-the-art performance in sound removal and vocal-imitation-guided source separation, while maintaining competitive results on language-queried source separation.
[arxiv paper]

























